1. Introduction
1.1 What is Paisley?
Paisley is an open-source framework to help IT or engineering teams quickly set up and deploy chatbots that incorporate team-defined data. It achieves this through Retrieval-Augmented Generation (RAG).
RAG is an approach for enhancing the capabilities of Large Language Models (LLMs) with an external store of (often proprietary) information1. With a RAG system, users make natural language queries that retrieve information from an external knowledge base. This retrieved information is then included in a prompt to an LLM, such as OpenAI's GPT-4o or Anthropic’s Claude 3.5 Sonnet.
Although a basic prototype RAG chatbot can be quickly created from numerous online tutorials and open-source libraries, deploying a production-ready chatbot involves a number of additional steps which require knowledge, libraries, and infrastructure to realize.
1.2 Use Case
Paisley is an open-source, configurable, “bring-your-own-cloud” alternative to the proliferation of closed-source, paid, and typically 3rd party-hosted RAG chatbot services. Our RAG “starter-kit” enables small IT teams rapidly configure, deploy, and evaluate internal RAG chatbots.
Paisley may be a fit in any scenario where there is a distribution of duties: a busy technical expert who may help to set up the chatbot infrastructure, an information owner who sets up the knowledge base, and the ultimate consumers of that information - other people with questions.
2. What is RAG?
Before looking at existing solutions for setting up a RAG chatbot, it may be helpful to better understand what RAG is and the various considerations that may impact any decision. For readers who are familiar with RAG, feel free to skip this section and refer back only for clarification on terms used.
2.1 LLMs
Generative AI and the LLMs that power it are a transformative technology. By prompting an LLM, a user is able to generate creative content such as articles, stories, and marketing materials.
It’s common for an LLM to provide authoritative yet inaccurate responses or “hallucinate”. LLMs are typically trained on a snapshot of the internet and thus unable to generate accurate responses to queries about current events or real-time data. Similarly, LLMs have no access to proprietary information not included in their training data.
Although LLM performance can be improved training through fine tuning, effective implementation requires a high level of technical skill, time, and cost.
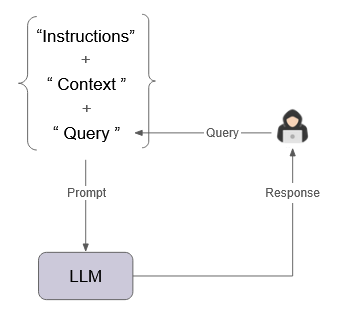
2.1.1 What is a prompt?
When using a chat interface, a user’s question (the query) is only part of what is submitted to the LLM. The query is combined with additional text (the context), and instructions within a prompt to guide the LLM in generating a response.

2.2 Basic RAG
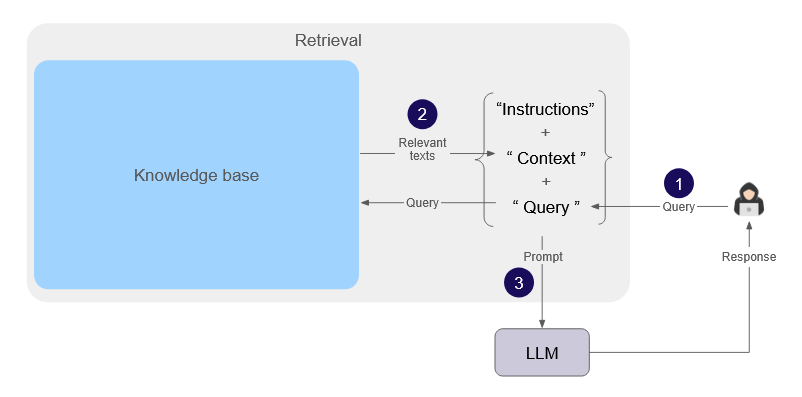
Most simply, RAG involves retrieving additional information about a user’s query and placing it into a prompt sent to an LLM as context.
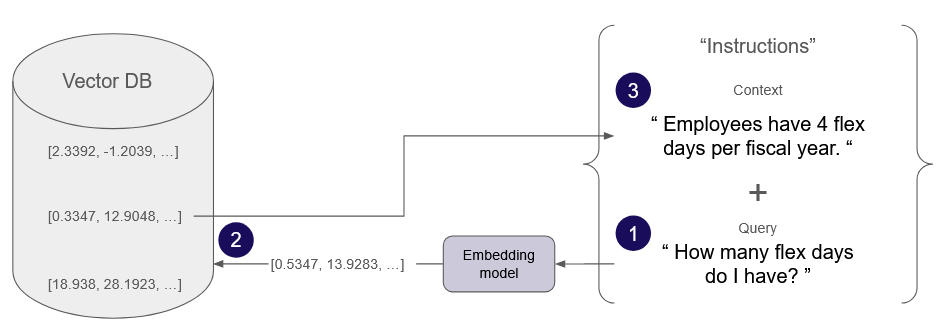
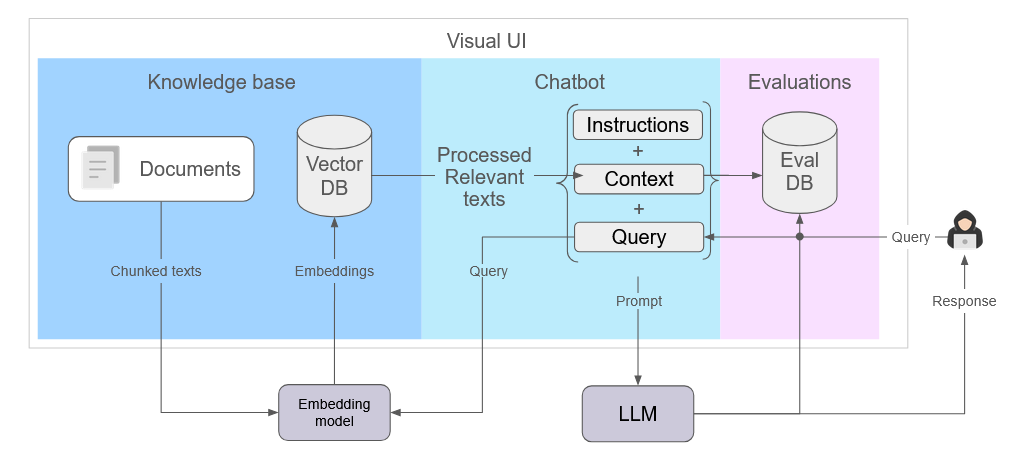
This additional information comes from one or more knowledge bases that serve as a “source of truth” for the LLM. This source of truth is typically proprietary data the LLM was not trained with, for example business rules or historical data that's not publicly available. Knowledge bases are created by breaking down files, such as a PDF, into smaller chunks of text. When a user submits a query (“1” in diagram below), relevant chunks are retrieved from the knowledge base(s). This retrieved text (“2”) is combined with the original query, into a prompt instructing the LLM to respond with information from the context. This prompt is then sent to the LLM (“3”) to generate a response which is based on (or grounded with) the retrieved information.
2.2.1 How does a knowledge base work?
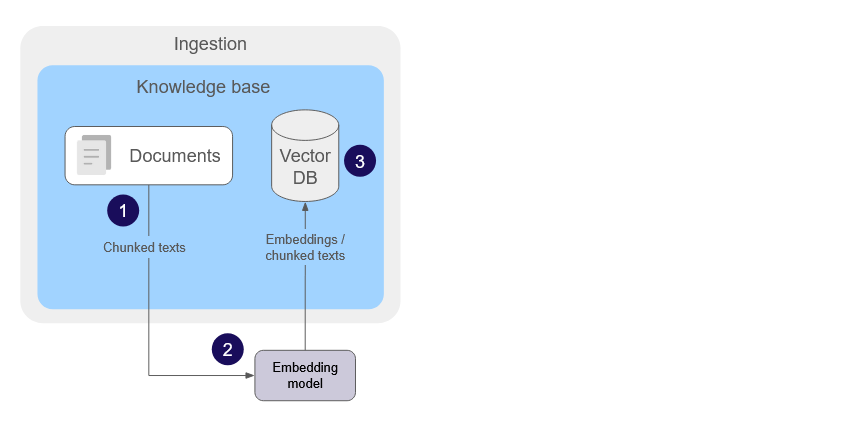
A knowledge base encompasses the documents a user wants the LLM to reference and a database for storing representations of those documents. The process of collecting, importing, and processing information from those documents is known as ingestion.
The first step in ingestion is breaking down the raw data into smaller pieces (chunking). How a document is chunked affects the overall performance of retrieval: large chunks may obscure detail, small chunks may lack semantic meaning. Documents with different content types (e.g., tables vs long-form text) may require entirely different chunking and embedding strategies to be effective.

The next step of ingestion is to convert chunked data into an array of numbers (known as embeddings or vectors) using an embedding model. An embedding model can be thought of as an algorithm, a set of steps which take an input (text, in this case) and produce an output (array of numbers). These numbers are a multi-dimensional array of hundreds or thousands of floating point values2. An embedding captures the semantic meaning of each chunk, allowing for more nuanced and efficient comparisons than using raw data.
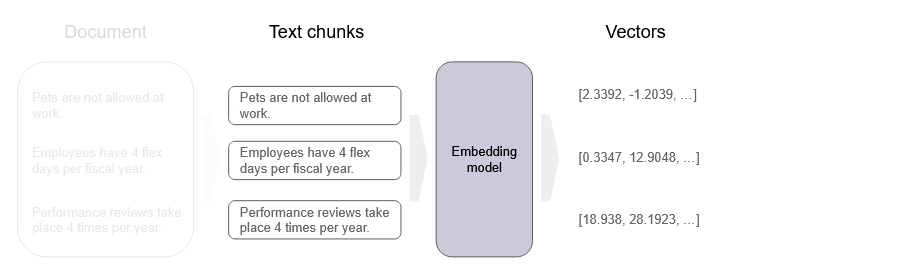
Similar chunks of data are represented by similar vectors.
In the final step of ingestion each chunk’s embedding is then stored in a vector database (a database optimized to store and retrieve vectors) along with the corresponding text of that chunk.

A summary representation of the ingestion process in a knowledge base is shown below.
2.2.2 Processing a query
When a user submits a query (“1” in diagram below), it is embedded using the same model that was used to create a knowledge base. The resulting query embedding is then compared against existing chunk embeddings in the vector database to find text chunks that are most similar (“2”). Through a process known as vector similarity search, each number of the embeddings is compared to calculate an overall number representing the level of similarity of the vectors, and the associated text. The retrieved text chunks are then combined as the context (“3”) with the user query to form a prompt that is sent to an LLM to generate a response.
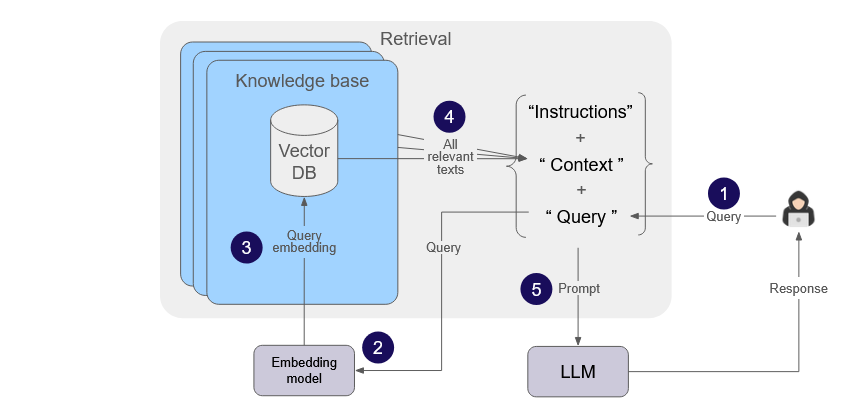
2.2.3 Summary of retrieval
In the diagram below, we summarize the steps involved in retrieval and discuss the addition of multiple knowledge bases:
- User submits a query.
- Query is embedded via the same embedding model used for ingestion. If different knowledge bases use different embedding models, the query will be embedded multiple times, once for each knowledge base.
- (The appropriate) query embedding is used for vector similarity search against the embeddings in each vector DB.
- Relevant text chunks are returned from vector similarity search of each knowledge base and combined.
- Instructions, context (all relevant text chunks), and user query are combined into a single prompt and sent to the LLM to generate a response.
2.3 Post-processing context
Above, we’ve outlined a relatively simple RAG process involving ingestion and retrieval prior to a response from the LLM. Additional knowledge bases might each represent different choices in how documents are ingested to best suit content type. If additional knowledge bases are added, the amount of retrieved context may also increase. Not all retrieved text content may be equally relevant to a user query. Thus, further processing of the retrieved context before submitting a prompt can significantly improve RAG performance3.
To reduce the volume of retrieved text, the least relevant context can be rejected, improving the quality of generated responses and reducing computational resources and LLM token costs. This process is known as similarity filtering.
The retrieved context may not be ordered, especially if context from multiple knowledge bases is combined. Through a process known as reranking, an embedding model compares the user's original query against each of the returned text chunks to determine which context is most relevant. Typically, only the top results are incorporated into the prompt sent to the LLM. More effective rerankers will incur a greater computational and LLM token cost.
Finally, the order of the retrieved context submitted to the LLM affects the quality of the final response. The most relevant context should be placed at either the beginning or end of the submitted context. Context placed in the middle can be overlooked by LLMs. This is commonly known as reordering.
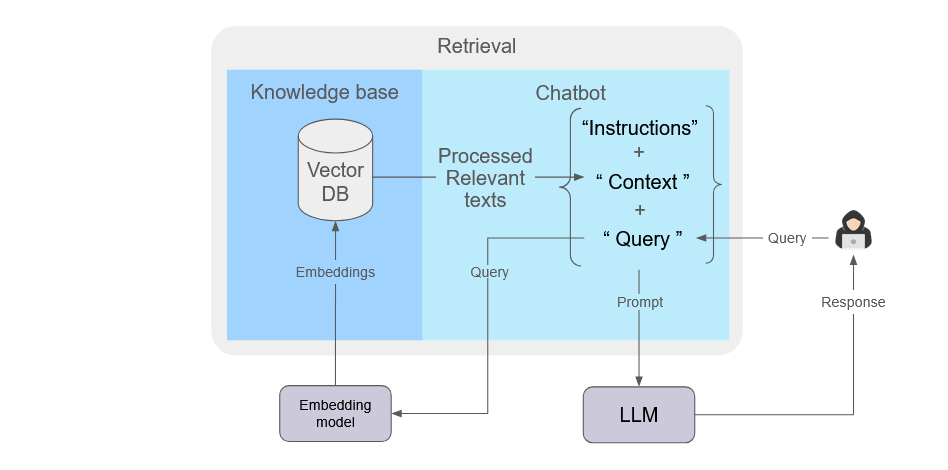
Different LLMs may have limitations on the amount of context they can process and perform differently depending on the prompt instructions provided with the context and query. The optimal configuration and combination of settings is heavily dependent upon the nature of the information, the format in which it is stored, and the specific queries users submit.
2.4 Evaluating a RAG system
Above, we’ve outlined a RAG process involving ingestion, retrieval, and post-processing of context prior to LLM generation. The complexity in RAG arises from the vast number of options available for even just those three initial steps, all of which can greatly impact the quality of the LLM response. As a result, a structured method for evaluating RAG performance is critical.
There are two key areas of evaluation:
- quality of the retrieved context (text chunks), and
- final answer generated by the LLM.
Ultimately, the best evaluations involve a team of subject matter experts who create a reference dataset identifying expected context and generated response for each query - a time-consuming and expensive process.
LLMs are increasingly capable of supporting evaluations with or without reference datasets4. Evaluation frameworks exist that utilize LLMs to judge each question, context, and generated response, and assign scores of relative quality. Consistently low scores across user queries indicate opportunities to improve RAG configuration options. As of the time of writing, the use of LLMs in evaluations is rapidly evolving.
3. Existing solutions
Due to the current pace of development in LLMs and related applications, the number of existing tools and solutions to facilitate RAG creation is vast. Generally, these solutions fall within two main categories: open-source libraries and hosted solutions.
3.1 Open-source libraries
There are numerous open-source libraries for developers building a RAG system, but LangChain and LlamaIndex are two of the most popular. Each allows you to build a near infinite number of RAG pipeline configurations, but their extensive flexibility creates implementation complexity for developers.
Open-source libraries exist for evaluating the quality of context and responses from RAG systems, ranging from lightweight command-line tools to fully-featured applications with visual UIs. These are generally distinct evaluation-specific packages that need to be configured and integrated as additional components to an existing RAG application.

In general, open-source libraries do not provide support for deployment. At most, they create a locally-hosted API endpoint for user interaction and testing. As a result, the burden of provisioning infrastructure to support the pipeline and creating an interface for it is placed on the developer.
3.2 Hosted solutions
Hosted solutions for deploying RAG chatbots that we reviewed exist along a spectrum from simple, focused products to flexible, configurable platforms encompassing a comprehensive variety of additional features such as fine-tuning and observability. The target audiences for these solutions range from an individual who both creates and consumes the chatbot as a personal tool, to a large company utilizing enterprise-scale chatbots for customer service or support.
Wherever they land on the spectrum, these solutions are hosted on the vendor’s infrastructure and require an organization to upload their documents for the vendor to process.
For our project we focused on the more targeted solutions better suited for a small organization, rather than enterprise platforms.
For example, Mendable (https://www.mendable.ai/) is a hosted solution that aligns well with our hypothetical use case. They simplify the process of configuring and deploying custom chatbots with an intuitive, web-based user interface. Their free feature set includes the ability to create a chatbot, upload documents that form a knowledge base, adjust basic configuration settings for this chatbot, view a history of past chatbot conversations, and access the created chatbot via a created React component or via a hosted API endpoint.
4. Introducing Paisley
We developed Paisley - an open-source RAG pipeline “starter kit” - to enable developers to quickly deploy and methodically iterate on the chatbots they create by providing an opinionated set of configuration options and RAG components. LLM-supported evaluations are included out-of-the-box to support knowledge base and chatbot testing.
In the table below, we’ve chosen a representative open-source framework (RAGFlow) and hosted solution (Mendable) to make a comparison of products that fit our use case for quickly setting up a RAG chatbot with a user-defined knowledge base.
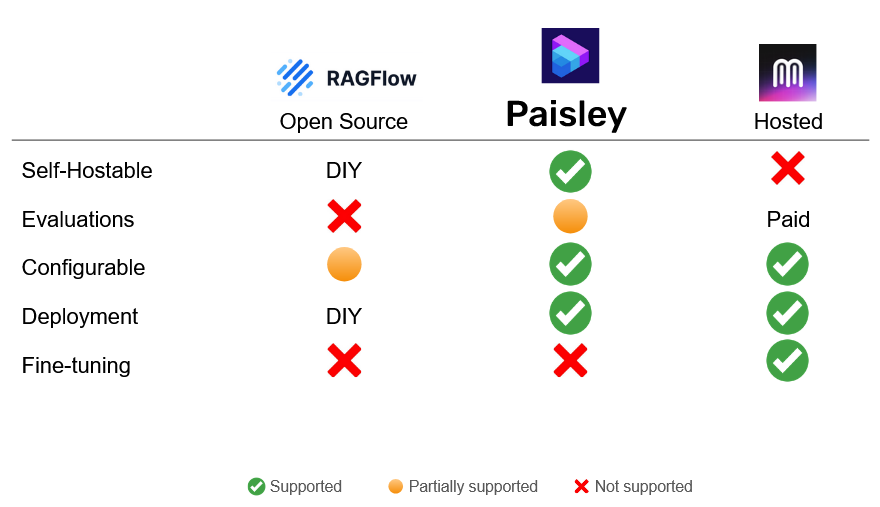
Given the complex, evolving open-source ecosystem, a user who wants to build and deploy their own RAG chatbot will need to assemble and integrate each of the various components by themselves. For a user who wants to maintain complete control of their proprietary data, this may be the best approach, but will require time and expertise to implement.
Our goal was to strike a balance between the overwhelming complexity of the fragmented open-source landscape and the limited flexibility of non-enterprise paid solutions.
Paisley can be broken down into three main configurable components:
- Knowledge bases
- Chatbots
- Evaluations
These components are accessible via a web-based UI that supports configuring, evaluating, and iterating RAG chatbots.
The brief video below provides an overview of the key Paisley components.
In addition, we provide a command line interface (see Section 4.4) to consolidate the process of deploying a Paisley on your AWS infrastructure.
4.1 Knowledge bases
A knowledge base is a collection of documents with similar content properties chunked and embedded according to the same configuration. Paisley allows users to create as many knowledge bases as they would like, providing the flexibility to ingest different types of data optimally.
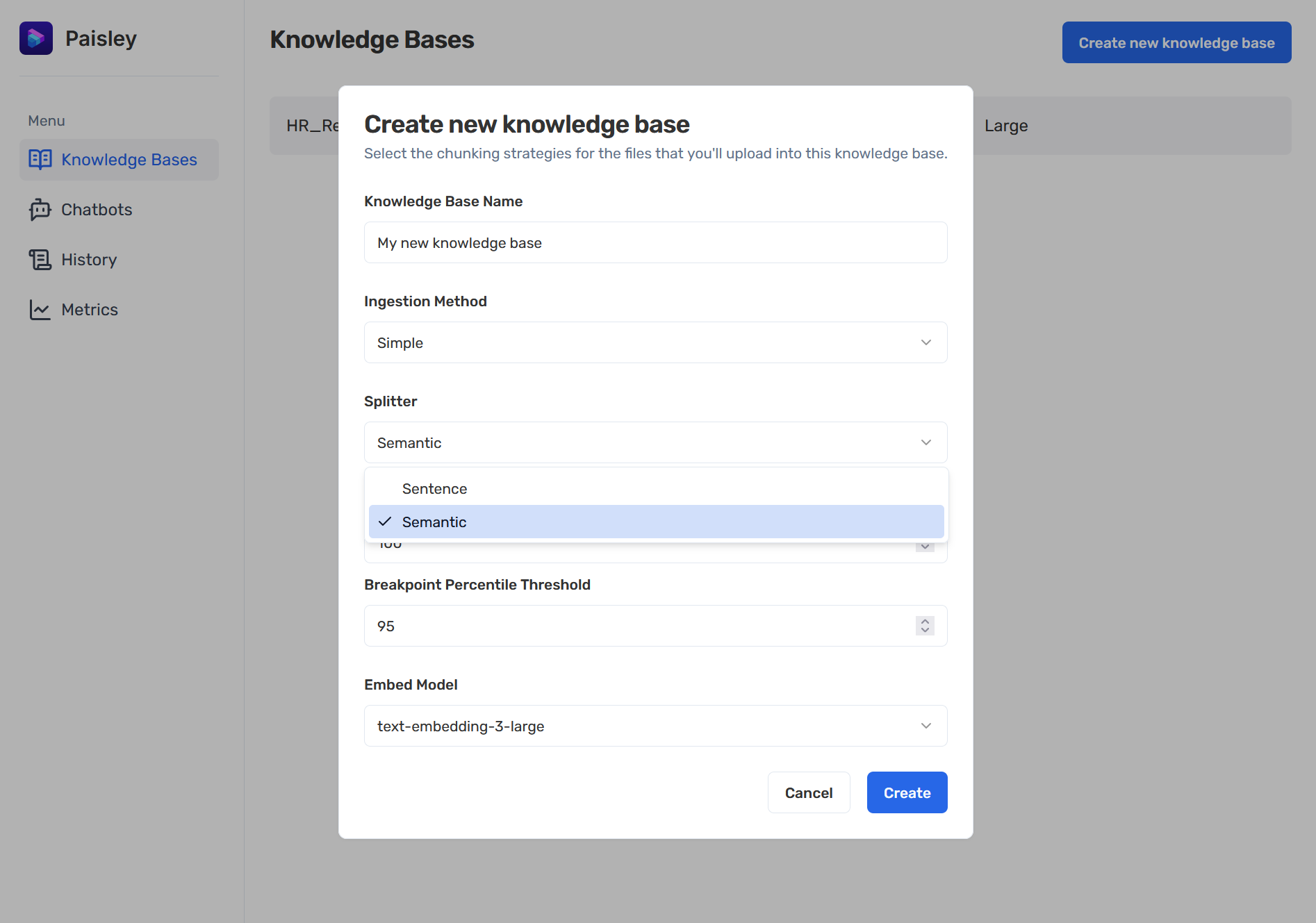
The way a document is processed and stored within a database has a significant impact on the overall effectiveness of the RAG system. We provide our users with three options to break down their data: sentence, semantic, and markdown.
The sentence splitter is designed to keep sentences and paragraphs together. Preserving the structure of natural language during the chunking process is better than arbitrary word length chunking strategies.
The semantic splitter uses an embedding model to compare the semantic meaning of sentences, then groups similar sentences into chunks. Note that the semantic chunking strategy utilizes an embedding model twice. First by embedding each sentence for similarity comparison and grouping, and again to create embeddings for each group.
The markdown splitter is implemented through the use of a 3rd party LlamaParse API. This external API can selectively apply more advanced strategies to convert images to text through Optical Character Recognition (OCR), and add markdown headings and structure to data from tables or figures. The returned markdown is then chunked and embedded by Paisley. While this approach allows for the effective ingestion of more complex files (e.g. table data), it relies on an external service and an LLM before embedding can occur. As a result, it is a time-intensive process.
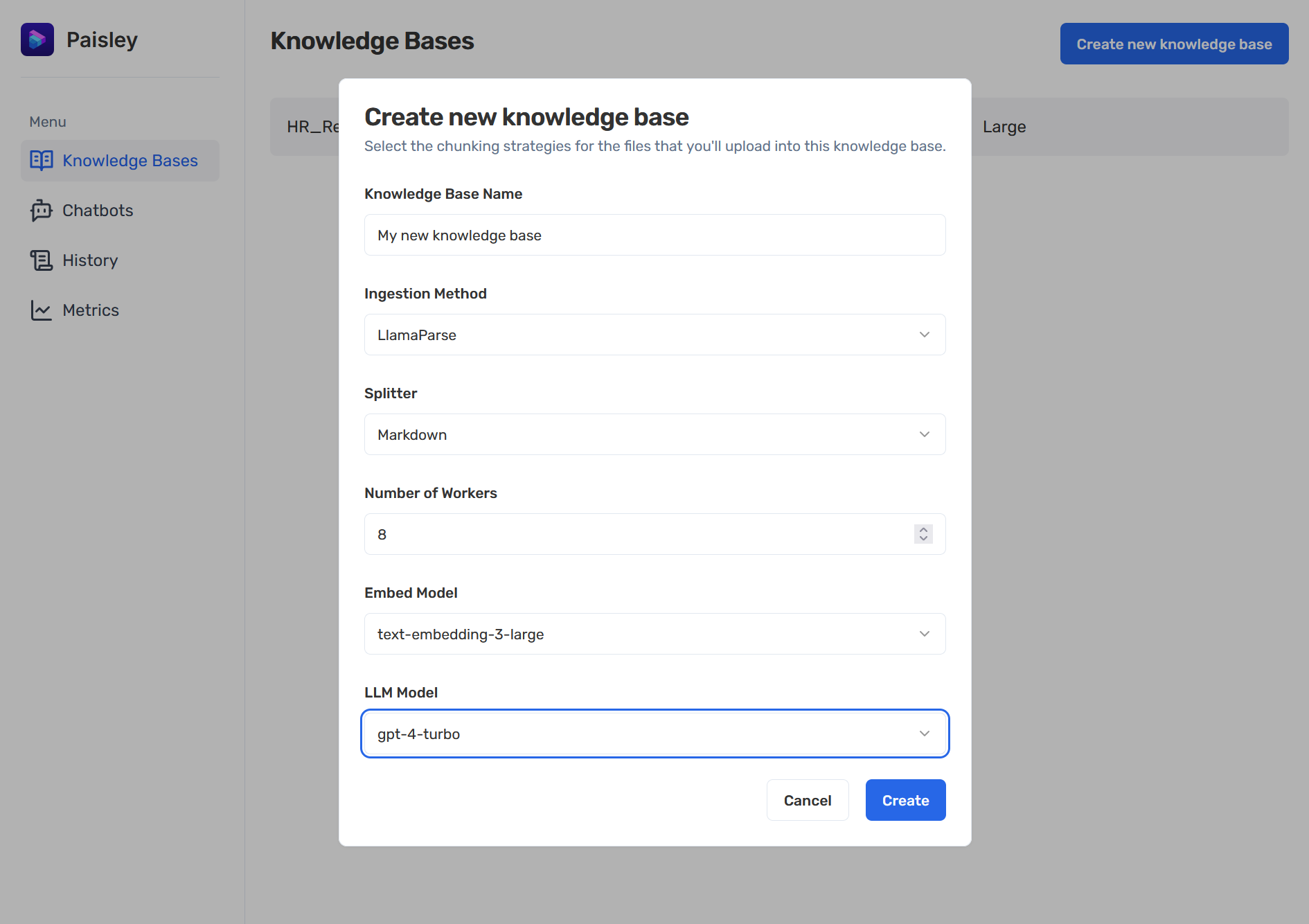
We also allow users to select from a variety of embedding models to find the best fit for their project.
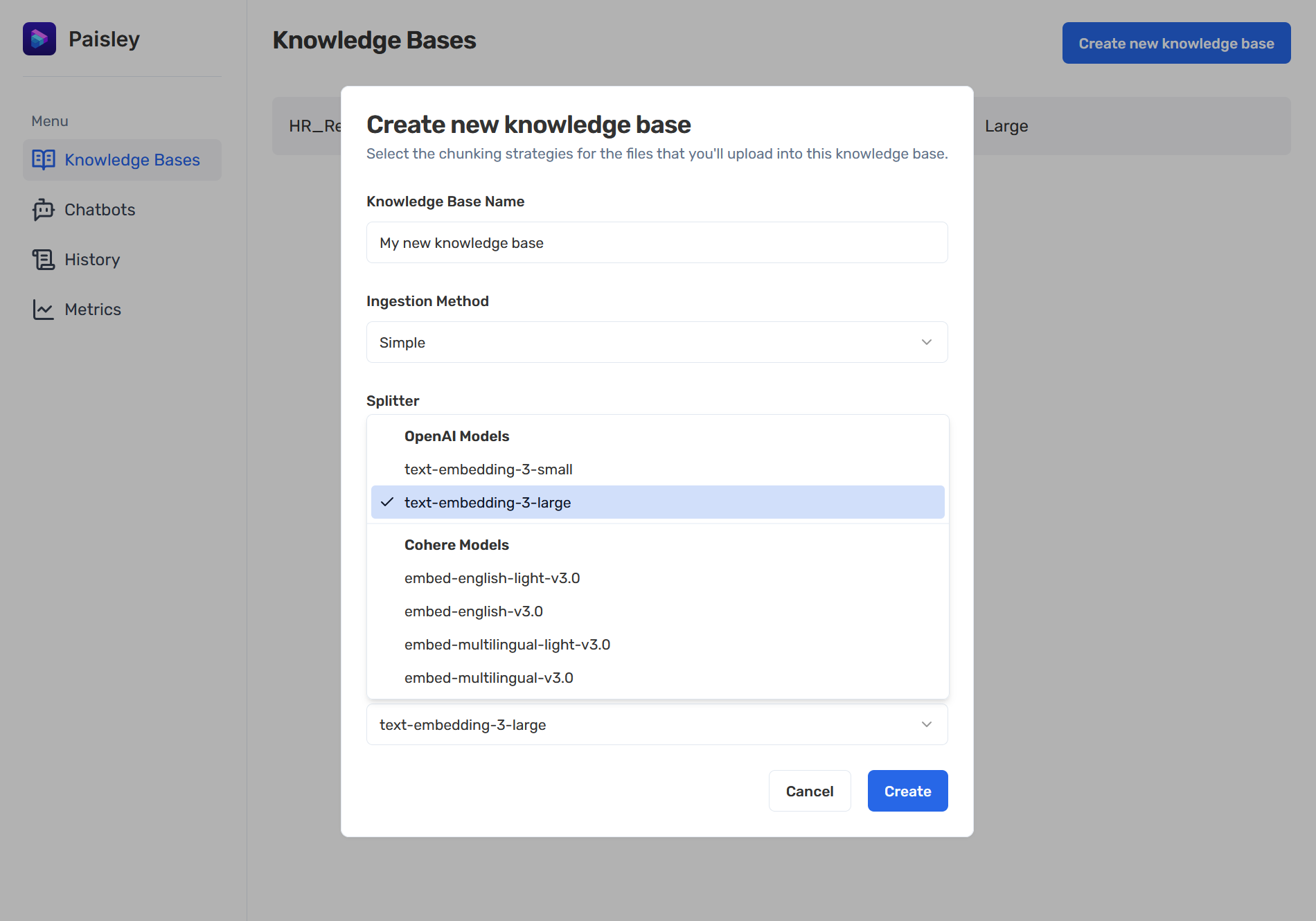
Together, these options empower users to evaluate various settings and rapidly iterate on the knowledge base configurations that are best suited to their content.
Once a knowledge base has been configured and created, users are able to upload their files to be processed according to these settings.
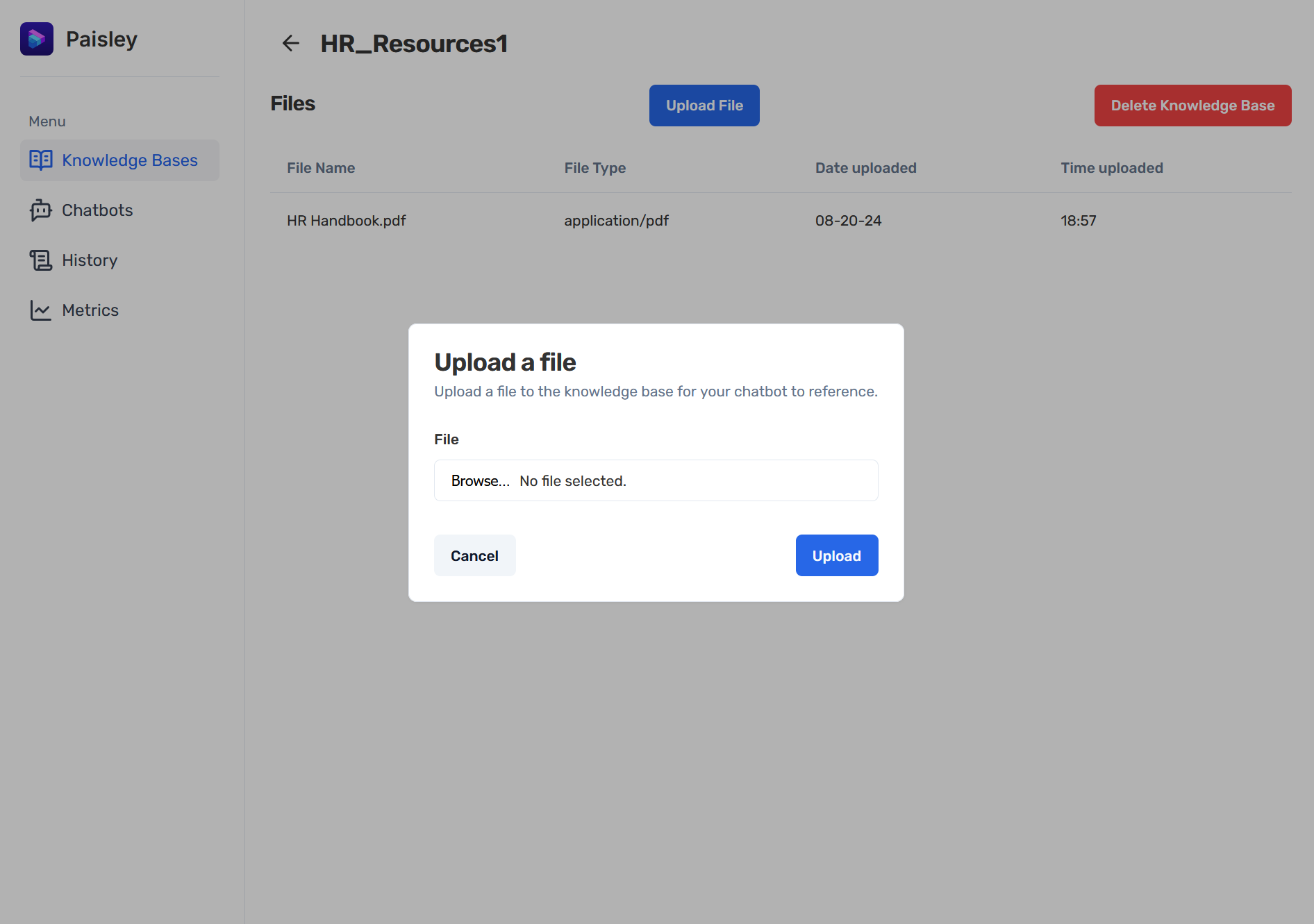
4.2 Chatbots
Chatbots connect to one or more knowledge bases to retrieve the relevant context for a user’s query, prompt a LLM, and generate a response.
Paisley allows users to create multiple chatbots, where each chatbot can be associated with one or more knowledge bases.
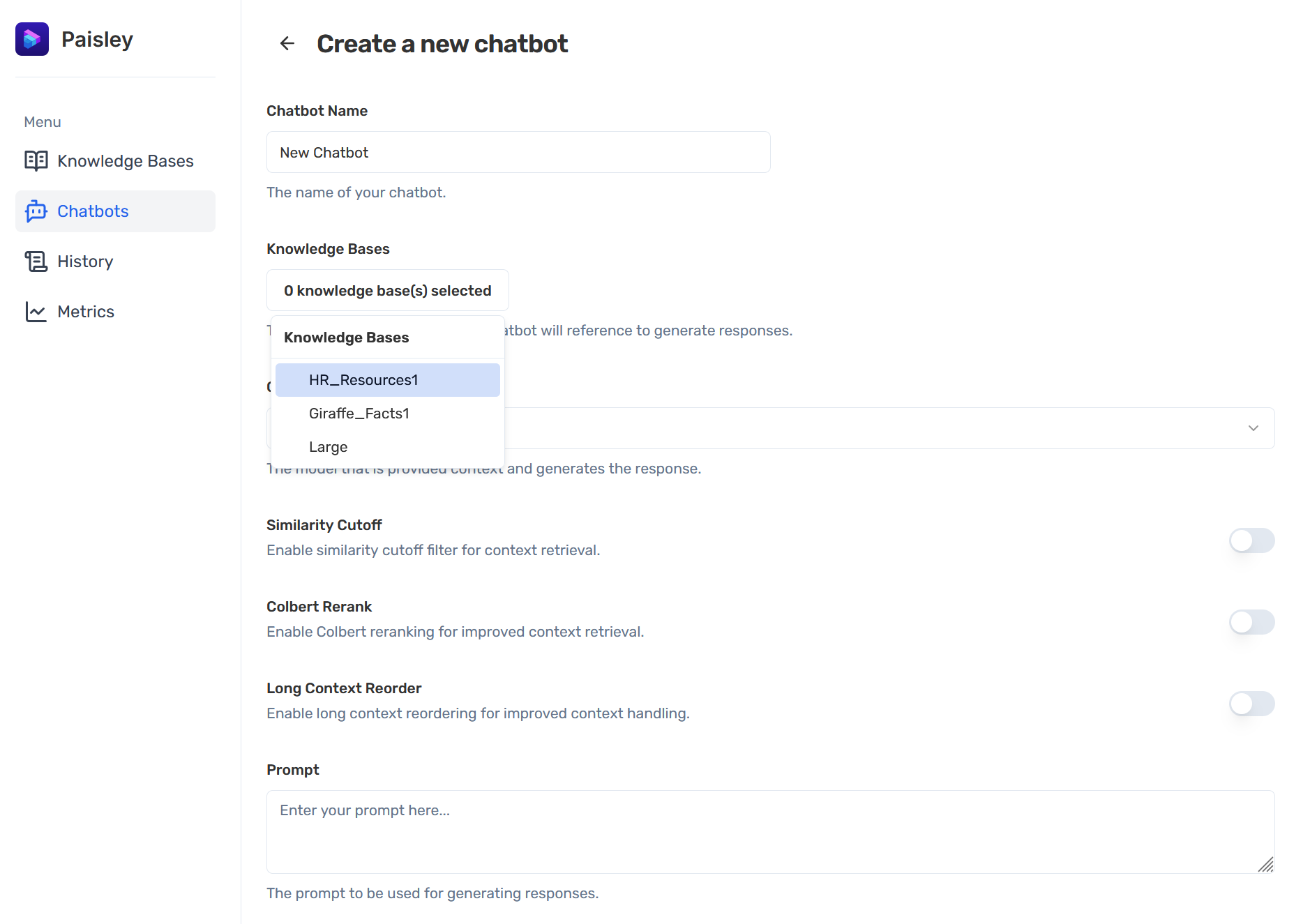
Users can associate the same knowledge base with multiple chatbots to facilitate the evaluation of various chatbot configurations.
Although context post-processing can improve RAG performance, it requires additional computational resources, increasing query response time. Use of the reranker will further increase token costs. For these reasons, all post-processing strategies are optional.
The similarity filter compares each retrieved context with the user’s query and scores the similarity between the two. It then discards retrieved context with similarity scores below a predefined threshold, ensuring only the most relevant context is used in the prompt sent to the LLM.
For reranking, we selected a reranking methodology known as ColBERT5. The collection of retrieved context is compared against the original user query and ranked in order of relevancy. The “top n” option defines the number of top results to send to the LLM. This is the most computationally and token/cost expensive of the post-processing options offered.
“Long Context Reorder” reorders the retrieved chunks prioritizing chunks providing broader, more comprehensive context so that longer, more informative content is given higher importance in the results.
Users can also define an instructive prompt that wraps the user’s query and the retrieved context; this form of prompt engineering defines how the LLM generates a response from the query and its retrieved context.
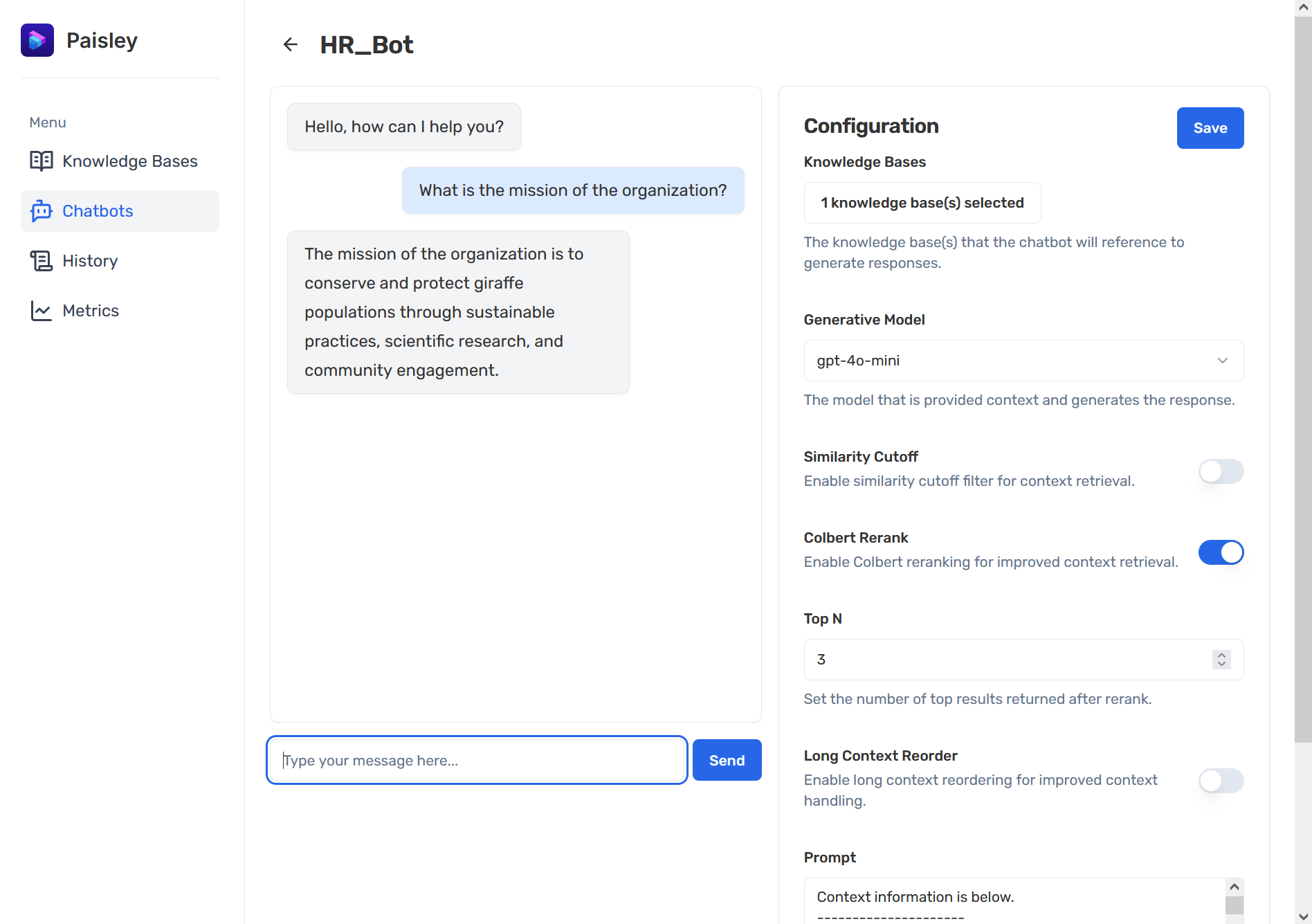
4.3 Evaluations
Given Paisley’s "quick-start" use case, we opted to include automatic, LLM-assigned evaluations. Whenever users query a Paisley chatbot, evaluation metrics are automatically calculated by an LLM. A history of all queries, associated context, generated LLM response, and metrics are visible on the History and Metrics pages.

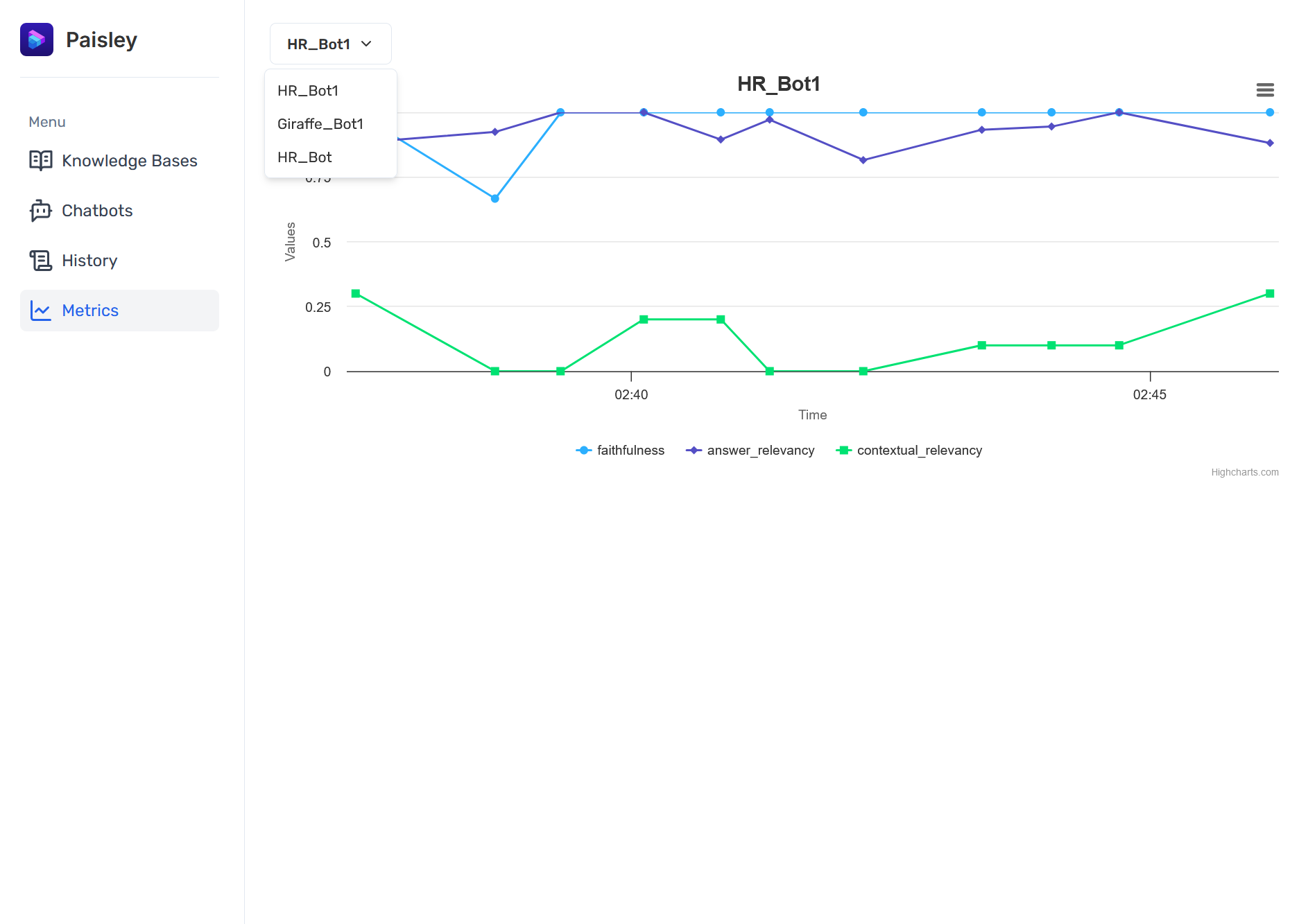
The user is able to compare a chatbot’s historical query performance and measure RAG performance over time with the provided evaluation metrics. Using these metrics as a guide, the user can quickly evaluate the performance of their chatbots and reconfigure as needed.
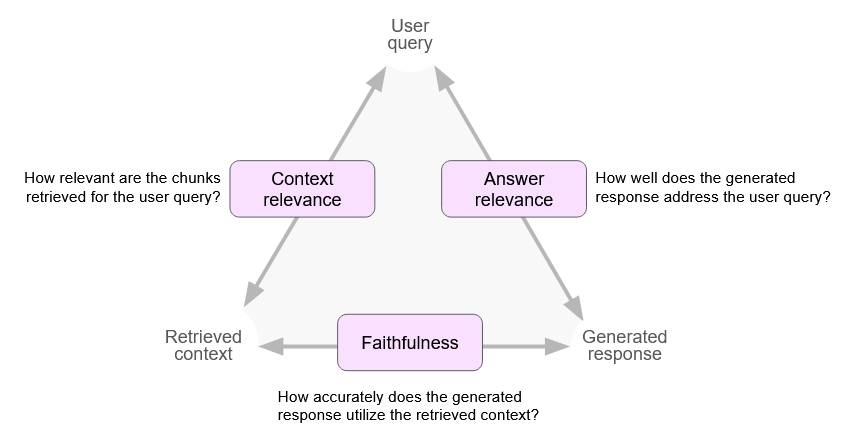
We’ve chosen three metrics to assess context retrieval and answer quality:
- Context relevance: How relevant are the chunks retrieved for the user query?
- Answer relevance: How well does the generated response address the user query?
- Faithfulness: How accurately does the generated response utilize the retrieved context?
Context relevance is a key consideration for someone iterating on a RAG system – what context was returned by the retrieval mechanism, and is it relevant to the user query? This is possibly the most important metric to consider in a RAG system as the quality of retrieved context contributes directly to the quality of the response.
Answer relevance is the first thing that the end-user of the chatbot will notice – is the chatbot’s response relevant to my question? Low answer relevancy can indicate poor retrieval quality or that the documents don’t have information relevant to the question.
Faithfulness is a measure of the generated response and how it relates to the retrieved context. A low faithfulness score might indicate the generated response includes hallucinations or makes use of information outside the retrieved context.
Scores are assigned to each metric for every query, the retrieved context, and generated LLM response. Answer relevance and faithfulness scores are assigned by an LLM using the RAGAs framework (https://docs.ragas.io/en/stable/). Contextual relevance scores are calculated by an LLM using DeepEval (https://docs.confident-ai.com/docs/metrics-introduction).
Considering that specific RAG use cases may want to utilize different metrics for evaluations, we offer the above metrics out-of-the-box while allowing users the flexibility to add their own. Paisley’s plug-in evaluation architecture allows users to remove unwanted metrics or add metrics by creating custom Python modules and updating an evaluation configuration file.
4.4 Command line interface
To use Paisley, you must have an AWS account. Before deployment, log into your AWS account, define IAM Roles, and create access keys for Paisley. Also ensure you have the AWS CLI, Node, and NPM installed on your machine.
Once these preliminary steps are complete you can download the Paisley application to your laptop. We document a series of steps and provide AWS CDK (Cloud Development Kit) scripts to streamline deploying (and tearing down) Paisley infrastructure. If desired, multiple concurrent instances of Paisley can be deployed onto their own distinct infrastructure using the same scripts.
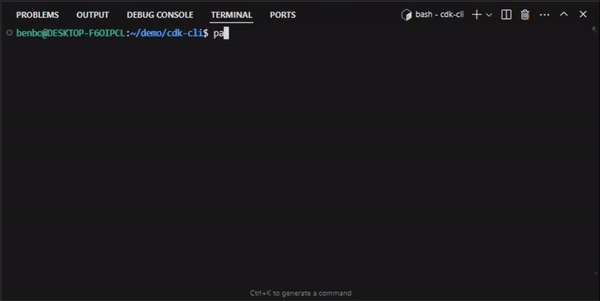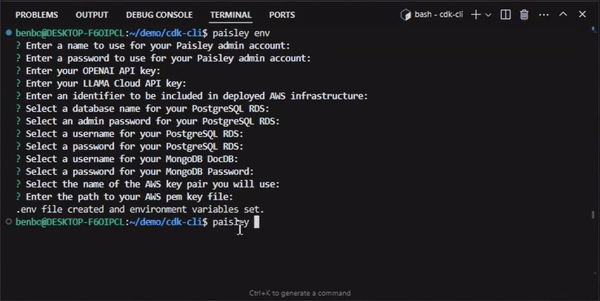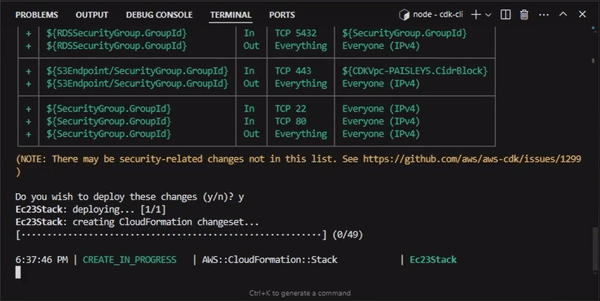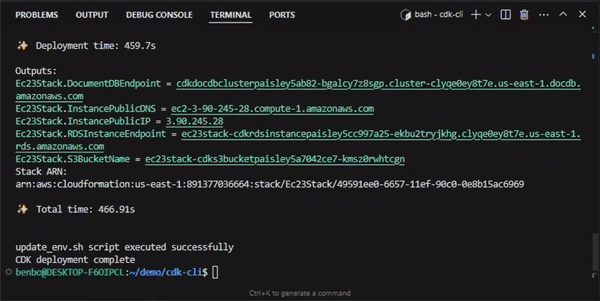
Once deployment is complete, the web UI discussed above is accessed by navigating to the assigned IP address with a web browser. This UI interacts with an API back-end which is also automatically deployed.
5. Paisley design
As mentioned in Sections 1 and 3, our primary goal was to create an easy to set up and deploy RAG chatbot “starter-kit” for small teams. In support of this objective, we picked AWS as a cloud infrastructure provider because it is commonly used and has all of the major building blocks we need.
5.1 Web architecture
Since Paisley is deployed on AWS cloud infrastructure we adopt a number of web application conventions to make our UI accessible and secure. A web server (Nginx) serves our UI. This UI interacts with the Paisley application server, which connects to our back-end databases. The EC2 instance which hosts both our web server and application server, and databases are described further in the rest of Section 5 below.
Given the latency inherent in external API calls to embedding models and LLMs, we opted to implement our UI as a single page application using optimistic UI updates, where sensible. The Paisley UI is built in React-Typescript using Tailwind CSS (https://tailwindcss.com/) and shadcn/ui components (https://ui.shadcn.com/).
To make the backend available to the UI, the EC2 instance hosts an API that the UI can access via JWT.
In alignment with general web design conventions, we implemented resource-oriented REST APIs through FastAPI as part of our application server. Our primary API resource names are knowledge-bases and chatbots.
With the architecture described above we conducted load testing on UI interactions which did not require external API calls (e.g., to models or LLMs) and we were able to support up to ~15,000 concurrent users. Although this figure is not a realistic representation of our core use case as a RAG chatbot, it is an indication that the underlying web architecture is sufficiently robust for our intended use case. We discuss load testing on the core chatbot query route in Section 6.1 below.
5.2 EC2 server
The core of Paisley revolves around a back-end server that provides API endpoints for our web-based UI and chatbot users. Our server also calls external APIs for embedding models and LLMs. To host this server we chose a (cost-effective) AWS EC2 instance. This long-running server gives us the flexibility to define a larger Elastic Block Storage size to maintain all of the necessary development libraries and dependencies. A single EC2 instance also provides us the option of converting to auto-scaling instances in future, if required.
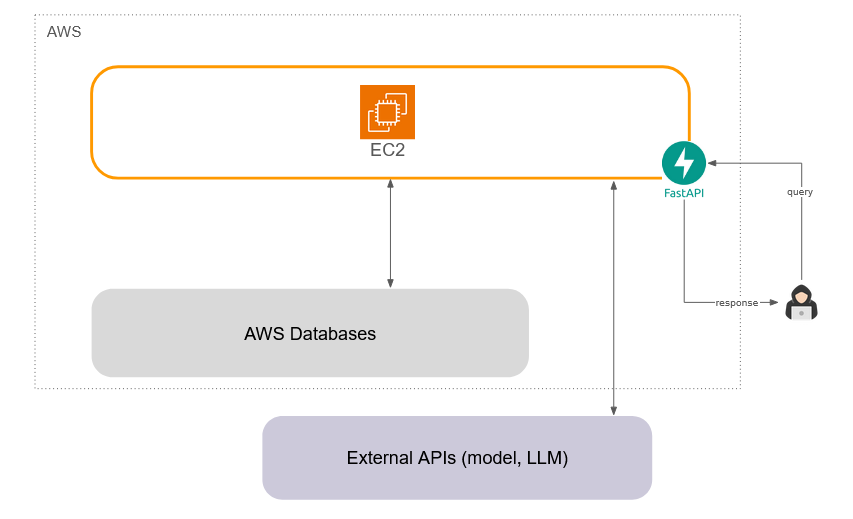
5.2.1 EC2 vs Lambda
An EC2 server also ended up being ideal for potentially long-running processes such as ingestion and evaluations data processing - both of which use external APIs to access embedding models. At first glance, there is potential for activity levels in these areas to fluctuate greatly and be “bursty” (e.g., a user may initially upload many files to create a knowledge base and then not ingest files at all once the chatbot is in use). As a result, we explored the use of AWS Lambdas (serverless functions).
However, from initial testing we realized that the 15 min runtime limit of Lambdas could become a constraint. Ingestion of a 4mb PDF had an average response time of 2 mins, which included all required external API calls for embedding. With larger files of 20+mb, we anticipated the 15 min runtime limit could be a concern.
Ultimately, we decided the additional complexity to work around Lambda runtime limitations was not required given our need for a long-running server instance to host our application server and UI.
5.3 Databases
From among the many AWS database offerings, we selected S3, DocumentDB (“DocDB”) and RDS. All of these are stable, long-term AWS database offerings that are used in many production applications.
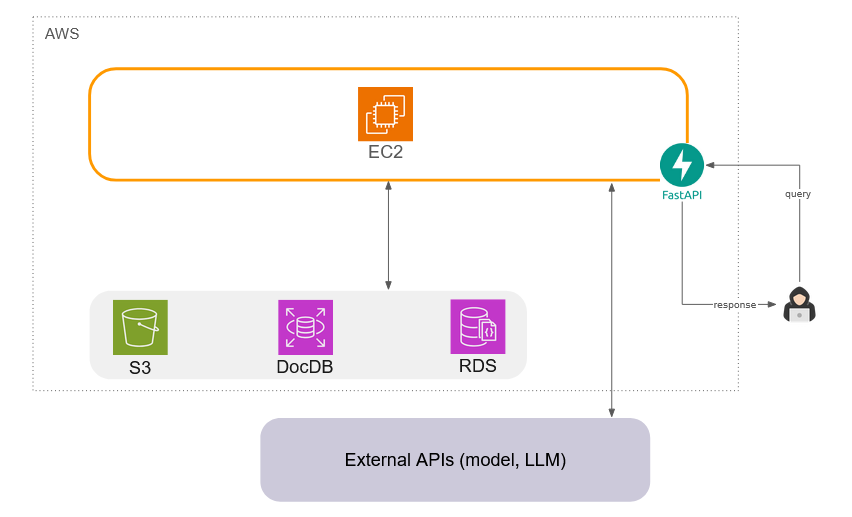
5.3.1 File uploads
AWS S3 is cost-effective long-term storage for documents uploaded to knowledge bases by users. Once ingested, these documents do not need to be accessed, and S3 provides many options for users to optimize cost for long-term storage.
5.3.2 Knowledge base and chatbot
Knowledge bases are composed of text chunks, the corresponding vector embeddings, and associated metadata identifying the original document. Each knowledge base also has a json configuration object which defines the documents within the knowledge base and how they were ingested. Different embedding models may store and retrieve data with slightly different data structures.
Chatbots have a similar json configuration object which defines included knowledge bases, post-processing, and LLM options for each chatbot.
To flexibly and scalably store data for multiple knowledge bases and chatbots, Paisley uses a schemaless noSQL database. DocumentDB provides built-in support for vector similarity search and easily stores json objects.
5.3.3 Specialized vector databases
We also considered the use of specialized vector databases, such as Milvus, Qdrant, Chroma, and others. Although specialized databases may have provided some performance benefit and simplified the retrieval implementation, we didn’t feel that the potential performance benefits would outweigh the drawbacks:
- Many of these databases are hosted solutions. Although some offer self-hosting options, this would have increased complexity.
- Feature set and offerings from some vector databases are rapidly changing - during the initial prototyping we conducted with some vector databases we noticed that SDK methods had deprecated only 2 weeks later.
The stable, established nature of DocumentDB is aligned with our goal of simplifying things for small teams. Use of a “standard” database simplifies troubleshooting and maintenance, and provides maximum flexibility.
5.3.4 Evaluations
Evaluations data includes a time-based history of user queries, retrieved context, LLM responses, and the corresponding evaluation metrics. This data was highly structured and was being stored with the goal of supporting future RAG performance analysis and comparison.
Paisley uses the AWS RDS relational database (PostgreSQL-compatible) to store evaluations data.
5.4 Paisley source code
Paisley’s back-end is written entirely in Python. Our API endpoints use the FastAPI framework on the backend to serve our API endpoints. Python was a logical language choice given the depth and breadth of existing libraries and frameworks in the Python ecosystem. It is the most common language for AL/ML-related projects.
As an open-source “starter-kit”, our intent was to provide small teams the flexibility to continue to build on Paisley, if desired. Thus, we prototyped various RAG libraries and frameworks to better understand their benefits. Ultimately, we chose LlamaIndex.
LlamaIndex exposes key RAG elements (nodes, indexes, retrievers) simply, allowing us to create and flexibly integrate multiple knowledge bases, each with unique settings, into a single chatbot. Built-in integrations also made it easy to connect ingested data, both raw and embedding, to a variety of databases. This flexibility allowed us to consider different RAG-related database solutions as discussed in Section 5.2 above. The library also helped streamline the implementation of the post-processing strategies discussed in sections 2 and 4 above. Finally, LlamaIndex has an active open-source community. Developers are able to implement, integrate, and share custom features they’ve created on LlamaHub making it easier for anyone to expand the scope of our project.
5.4.1 Knowledge base component
Our application is broken up into several components. The knowledge base component interacts with DocumentDB to:
- store and retrieve knowledge base json configurations, and
- store text chunks and associated embeddings for retrieval.
The knowledge base calls an external API and passes it text chunks from the document. The embeddings returned from that API are received by the knowledge base component and stored within DocumentDB.
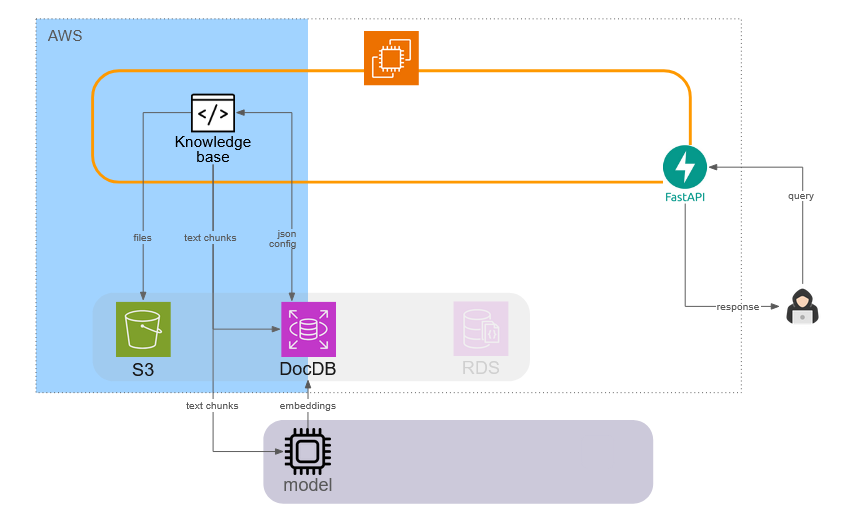
5.4.2 Chatbot component
The chatbot component accesses its json configuration files from DocumentDB. This component then takes the user query, sends it to an external API for embedding, and uses the result to search DocumentDB. Relevant text chunks retrieved from DocumentDB are then combined with the user query and instructions, and sent as a prompt to the LLM. The returned response is then sent to the user.
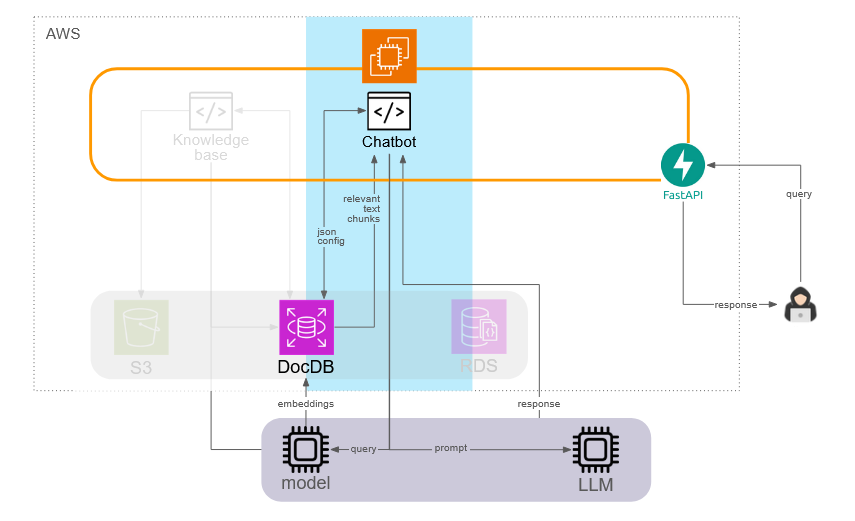
5.4.3 Evaluations component
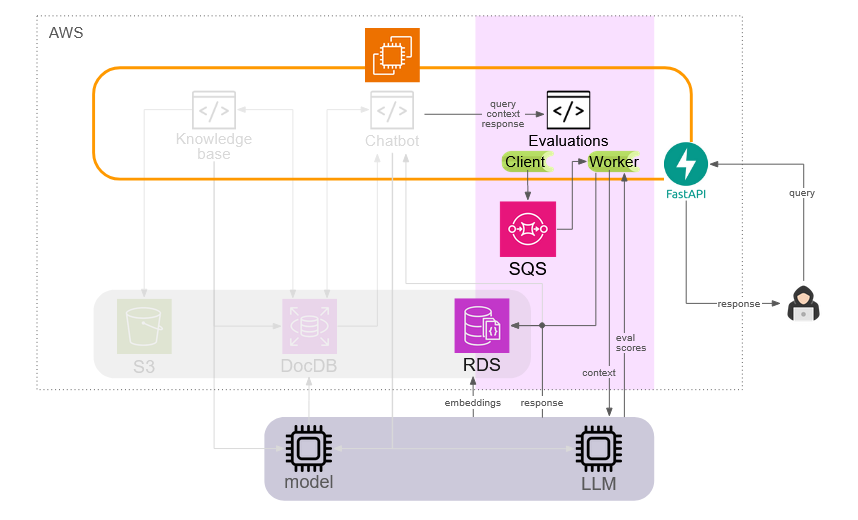
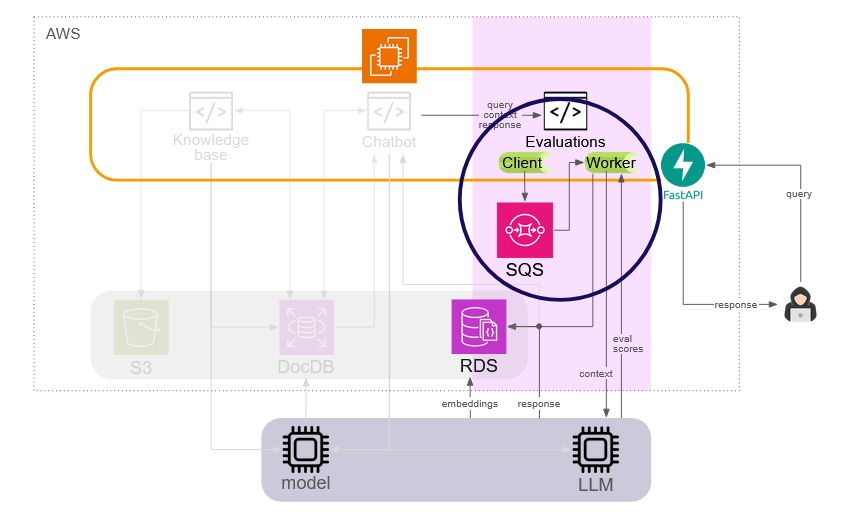
The evaluations component is the most distinct from the other two components. It receives query, context, and response information derived from the chatbot component, loads the appropriate evaluation libraries, and leverages LLMs to calculate the evaluation metrics discussed in Section 4 above. This process can be time-consuming as it relies on external APIs. As a blocking operation, it would significantly delay query response to the user. As such, we serialize this information as a background processing task via a Python Celery client. Celery is a popular task queue in Python that can be used to quickly implement background tasks.
AWS SQS (Simple Queue Service) is used as a message broker to store tasks which are then processed by the Celery task worker. This task worker then executes evaluations tasks and persists the data within RDS so that it can be queried and retrieved by the UI.
Additional discussion and rationale on this architecture can be found in Section 6.1 below.
6. Challenges
6.1 Background processing
After our initial prototype implementation, we conducted load testing on Paisley. While testing our chatbot query route using knowledge bases with a half dozen large documents (from ~12 mb to ~20 mb) we noticed increasing latencies up until timeouts at 120 seconds. Based on the configuration options chosen, we realized that the amount of context retrieved would increase significantly with the number and size of the knowledge bases configured. Since we had chosen to pursue LLM-assigned evaluation scores, each user query also required additional external API calls to an LLM for evaluations scoring. The amount of context retrieved is proportional to the size and number of documents within the knowledge base, and the number of external API calls is directly proportional to the amount of retrieved context. Our initial implementation did not include background tasks for evaluations. Evaluations was a blocking operation and our query latency was growing proportionally longer as context increased.
Our solution to this challenge was the architecture described in Section 5.3.3 above: to execute all evaluations-related processing as background tasks with Celery as a task queue and AWS SQS as a message broker. This change allowed the numerous evaluations-related API calls to be made in a non-blocking fashion, significantly improving query response times.
An added benefit was that subsequent testing demonstrated an increased number of concurrent users (50+) that our AWS Paisley infrastructure could handle - this was almost double (1.8 times) the initial number of concurrent users (~30) as compared to our prior architecture. This improvement more than allows for a small organization in our use case to satisfy internal demand for immediate answers, especially considering number of true concurrent users to likely be much lower.
6.2 Modular plug-in architecture for evaluations
There are many open-source evaluations libraries and frameworks available. To enable a solution that would be quick and easy for our intended use case, we explored LLM-automated evaluation scoring.
After prototyping with some libraries, we initially decided to integrate the RAGAs Framework into Paisley. In alignment with our “quick-start” objective, RAGAs worked well for users with no reference dataset of expected questions and answers. We also liked the level of resolution provided by the automated scoring. Where some libraries seemed to return the same score for every query/context/result, the metrics returned by RAGAs were more nuanced. However, after working with RAGAs, we also realized that without a reference dataset the only automated metrics available were LLM-response evaluation metrics. To incorporate a context evaluation metric for users without a reference dataset, another evaluation package was necessary.
We realized that the need to compare, and possibly utilize, different evaluation packages is an inherent challenge of RAG development, especially given the current pace of evolution in the tools and libraries.
Our solution to this challenge was to implement a flexible “plug-in” architecture for evaluations. A json configuration file defines any number of python modules (files) to be loaded and executed by Paisley. The user can create a custom evaluation function which takes Paisley-provided inputs - a user query, retrieved context strings, and generated LLM response - and produces as output some quantitative score. These functions can be implemented directly by the user, if desired, or they can import and leverage any 3rd party libraries. Paisley will execute all included evaluation modules and log the responses to the same evaluation database. Configured scores will be visible within the UI.
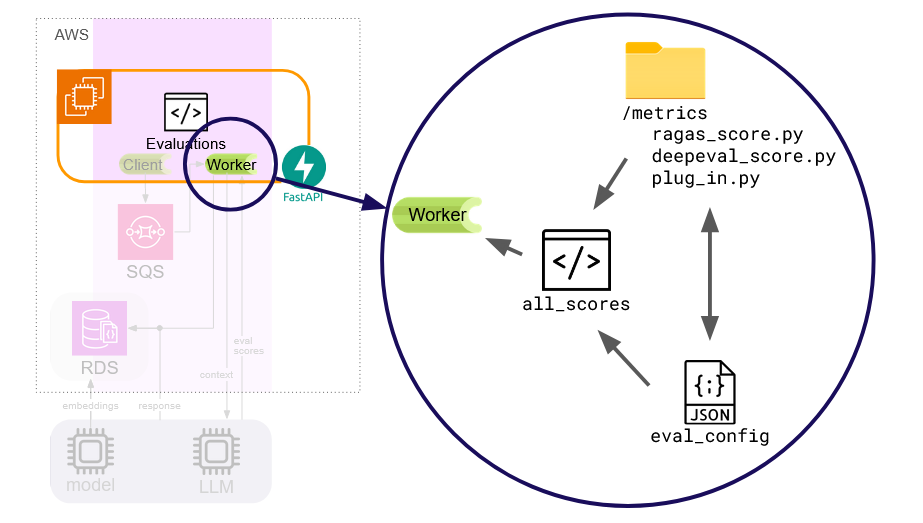
This solution allows us to provide the user with an initial evaluations functionality out-of-the-box, and also the flexibility to extend Paisley as needs or tools evolve. Given the importance of evaluations in establishing and maintaining a usable RAG chatbot, we feel this plug-in architecture helps to future proof this component of Paisley.
7. Future work
Retrieval Augmented Generation is a rapidly evolving domain in AI engineering and there are many features that could improve Paisley. We discuss some of the opportunities we’re most excited about below.
7.1 Amazon Bedrock
Bedrock is an AWS service that hosts a variety of pre-trained models and LLMs - both closed-source and also open-source. Not only would integration with this service provide our users with more embedding models and LLM options for the RAG pipelines they develop with Paisley, but the option to host open-source models in Bedrock would ensure user’s private data remains secure. In addition, Bedrock allows users to fine-tune models with their private data so they better meet their specific needs.
7.2 Pre-retrieval processing
One problem that arises when retrieving semantically similar embeddings is that the structure of a user’s query and the chunks we wish to compare it to are vastly different. For example, the differences between a one sentence long user query and a five sentence long chunk of the original document are vast. Comparing the embeddings of a user’s one-sentence query to five sentence or longer chunks from the original document is a bit like comparing an apple to an orange. The different lengths of the two pieces of text introduce a layer of variability that can harm retrieval performance. There are two possible solutions, both leveraging the generative abilities of LLMs6.
One solution to this problem, known as query rewriting, is to first have an LLM generate variations on the user’s query. This can include re-phrasing the query, making it more specific, or trying to expand or use alternate phrasings. In this way, additional content is created to further improve retrieval.
Another solution to this problem, known as HyDE (Hypothetical Document Embeddings) also involves the use of an LLM to generate content. However, rather than generate additional questions, in this scenario an LLM is prompted to generate a "hypothetical" answer. This answer may contain factual inaccuracies, but should possess the longer content and keywords more representative of an embedded text chunk. The hypothetical answer is then embedded and used for vector similarity search to improve retrieval.
7.3 Golden dataset evaluations
RAG and LLM evaluations are topics with considerable depth and developing best practices. Golden datasets or reference datasets are predefined queries and answers (sometimes including context). Ideally, these are supplied as human-approved content, but can also be gathered from human-approved RAG query responses, or even synthetically generated by an LLM. These datasets are used as a consistent baseline against which all future golden dataset evaluations and RAG responses can be compared. This tool improves the long-term monitoring of RAG chatbots. Having such a golden dataset as a baseline also allows improved RAG configuration testing since having a consistent dataset on which to compare queries and answers improves comparability of assessments between configurations.